
Llama2 7B 찍먹

0. 참고 및 사전 준비
- 테스트 사양 : 맥북 m2 8기가 메모리
- Meta Website Llama2 다운로드 신청
- Llama Repository 다운로드 진행
- llama2.c Repository Llama2.pth -> llama2.bin 변환 및 실행
1. 시식 방법
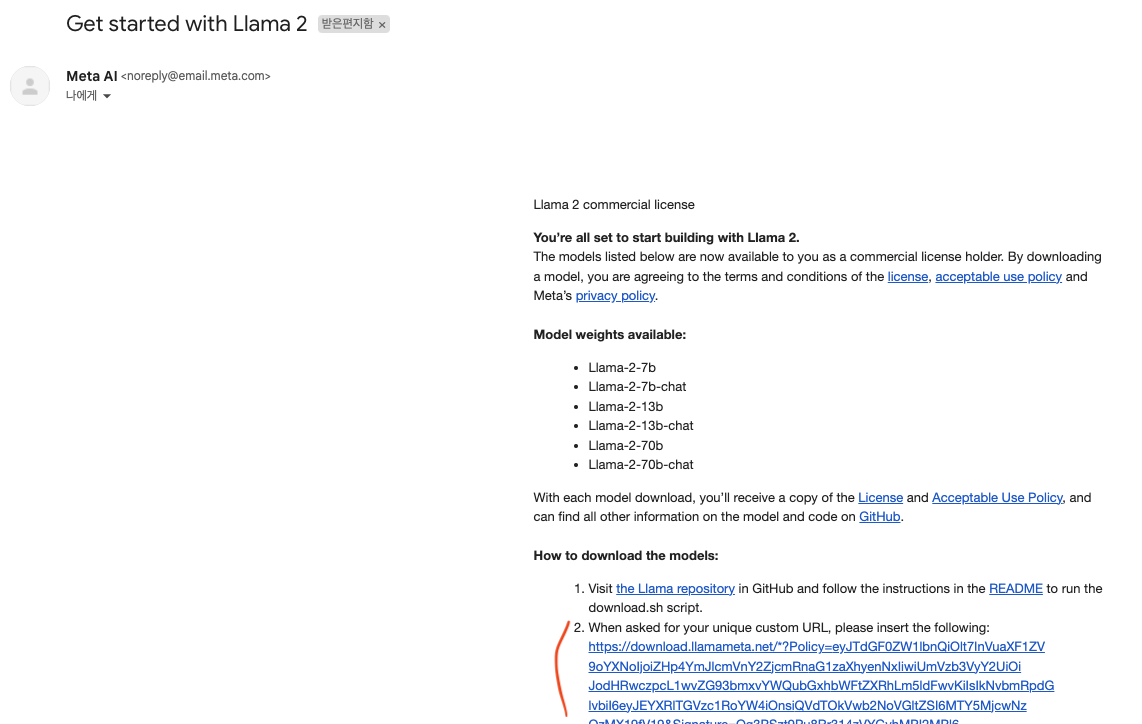
Meta AI로부터 회신
![메일화면]()
- 회신된 메일에서 주요 URL에 빨갛게 표시된 부분 복사
- Llama Repository 다운로드 해둔 경로의 download.sh 실행
- 앞서 복사한 주요 URL 입력
- 입력하면 아래와 같이 다운로드할 모델 선택 멘트 출력
1
Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: 7B(입력)
- 해당 포스트에선 7B 테스트 진행하기 위함으로 7B 입력
- 다운로드가 완료되면 llama2.c Repository 다운로드 경로로 다운받은 “llama-2-7b” 폴더 이동
1 2
pip install -r requirements.txt python export_meta_llama_bin.py llama-2-7b llama2_7b.bin
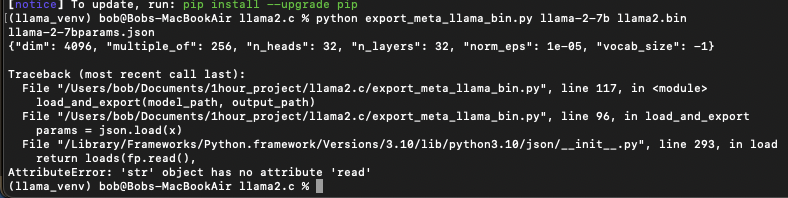
에러 발생
![export_bin_error]()
- export_meta_llama_bin.py 코드 수정
1 2 3 4 5 6 7 8
## python3.10 기준 def load_and_export(model_path, output_path): print(model_path + 'params.json') with open(model_path + '/params.json', "r") as f: x = f.read() print(x) params = json.load(x) -> params = json.loads(x) print(params)
- 재실행시 정상적으로 추출되는 것 확인
1
2
3
4
5
# source build
make run
# run
./run llama2.bin
2. 시식 후기
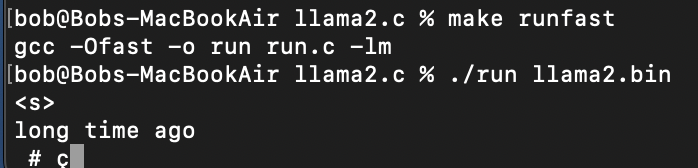
- long time ago 입력 후 1분간 대략 2개의 토큰 #과 알수없는 점달린 c 토큰이 생성되었다
- llama2.c repository 작성된 글이다.
1 2
This ran at about 4 tokens/s compiled with OpenMP on 96 threads on my CPU Linux box in the cloud. (On my MacBook Air M1, currently it's closer to 30 seconds per token if you just build with make runfast.)
- 그러하다 맥북으론 30초에 1토큰이 한계다, 여기까지 알아보자
- 제대로된 테스트는 GPU가 달린 서버에서 진행해보자