
0.프로젝트 정의 및 개발 환경
- 프로젝트 정의 : 1900년대 문서들부터 최신 문서까지 약 1,000건의 문서를 기반으로한 RAG 구축
- 개발 환경 : Ubuntu
- 활용 프레임워크 : Langchain
- 활용 LLM : OpenAI API
- Vector Store : MILVUS(chromadb, pinecone)
- 데이터 형태 : Source로 사용될 문서는 1건의 csv 문서, 1건의 excel문서와 PDF 문서들
1. 검색 고도화 방안 탐색 - 데이터 구조 업데이트
- 빠르게 구축만 진행하고 RAG 구조에 대해 이해 미흡으로 좀 더 이해하고 잘할 수 있는 방법을 탐색
- RAG 구조
- Chain에 질문 입력 시 질문을 Embedding하여 Vector Store에 검색한다.
- 질문과 유사한 Embedding을 가지는 문서를 k개 추출한다.
- 추출된 문서 k개를 요약한 후 prompt와 합쳐 llm에 전달한다.
- llm에서 생성된 결과를 출력한다.
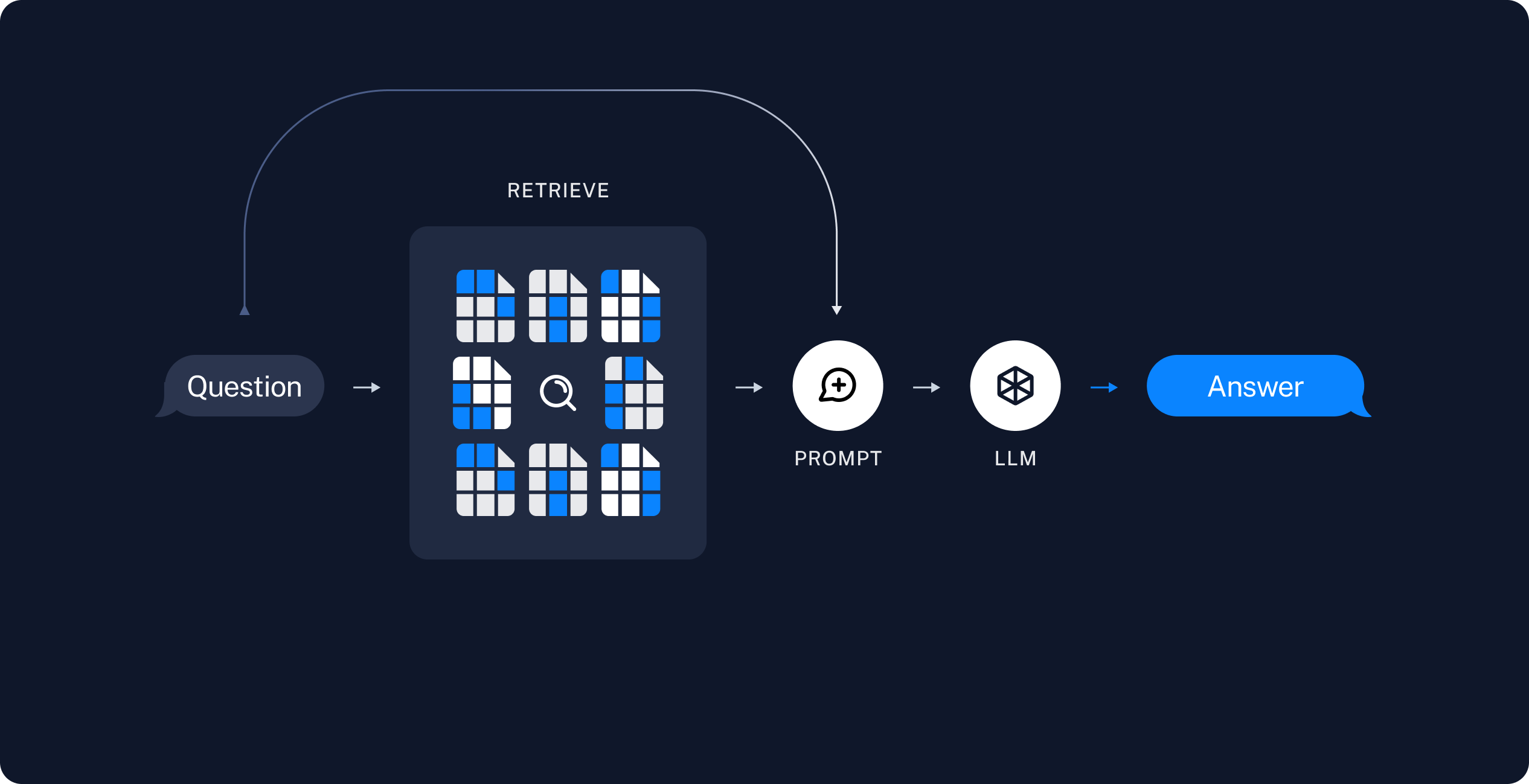
- 따라서 좋은 응답을 만들기 위해서는 좋은 문서를 추출하는 것이 필요
- 좋은 문서는 사용자가 입력한 질문의 답이 포함된 문서라고 정의 할 수 있음
- 다만 data loader를 통해 구축된 CSV, EXCEL은 핵심 용어 외에 불필요한 내용들이 반영되어 있어 정확하게 유사도를 비교할 수 없을것으로 판단
- 따라서 핵심 키워드만 page_content로 남기고 전체 내용은 metadata로 이동하여 문서 식별 후 page_content와 metadatd를 교체하여 활용할 수 있게 진행
- 이에 따른 vector store 재구축 진행
- 추가로 1) PDF 문서의 띄어쓰기가 어색하게 되어 있는 경우들이 많아 띄어쓰기에 대해서 재처리를 진행해주고, 입력시에서 동일한 띄어쓰기 방식이 적용될 수 있도록 함
- 추가로 2) 추후에 활용하기 위해 metadata에 카테고리 추가
2. Vector Store 재구축
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import pandas as pd
excel_df= pd.read_excel(f"{excel_file}.xlsx", index_col=0)
excel_loader = DataFrameLoader(excel_df, "임베딩에 사용될 컬럼명")
excel_data = excel_loader.load()
# metadata 통일을 위한 작업
for doc in excel_data:
doc.metadata["source"] = f"{excel_filename}.xlsx"
doc.metadata["date"] = f"{date_from_data}" # 20240301
doc.metadata["page"] = f"{excel_row_num}"
# 카테고리 추가
doc.metadata["category"] = "EXCEL" #f"{인물 그룹, 법규, 책, 문서 등등 구분}"
# 초기에 활용했던 내용은 해당 column으로 이동
# doc.page_content엔 검색에 필요한 키워드만 존재
doc.metadata["full_content"] = f"{doc.page_content} - {해당 content의 설명}"
results = vectorstore.add_documnents(excel_data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
csv_loader = CSVLoader(file_path=f"{csv_filename}.csv")
csv_data = csv_loader.load()
"""
# csv 파일 구조
# 컬럼1 | 컬럼2
# 데이터1 | 데이터2
# 데이터3 | 데이터4
print(csv_data[0])
Document(page_content='\ufeff{컬럼1}: {데이터1}\n컬럼2}: {데이터2}', metadata={'source': '{csv_filename}.csv', 'row': 0})
"""
# metadata 통일을 위한 작업
for doc in csv_data:
doc.metadata["source"] = f"{csv_filename}.csv"
doc.metadata["date"] = f"{date_from_data}" # 20240201
doc.metadata["page"] = f"{csv_row_num}"
# 카테고리 추가
doc.metadata["category"] = "CSV" # f"{인물, 법규, 책, 문서 등등 구분}"
# 생성에 활용될 전체 내용
doc.metadata["full_content"] = doc.page_content
# 검색에 필요한 핵심 키워드만
doc.page_content = f"{doc.page_content에서 추출한 핵심 키워드}"
results = vectorstore.add_documnents(csv_data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# PDF파일의 띄어쓰기 보정 라이브러리 설치
# pip install git+https://github.com/haven-jeon/PyKoSpacing.git
from pykospacing import Spacing
spacing = Spacing()
pdf_loader = PyPDFLoader(f"{pdf_file}.pdf")
pdf_data = pdf_loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk, chunk_overlap=overlap)
pdf_data = text_splitter.split_documents(pdf_data)
# metadata 통일을 위한 작업
for doc in pdf_data:
doc.metadata["source"] = f"{pdf_filename}.pdf"
doc.metadata["date"] = f"{date_from_data}"
# 카테고리 추가
doc.metadata["category"] = "PDF" # f"{인물, 사전, 그룹, 법규, 책, 문서 등등 구분}"
# metadata 일치용으로 추가
doc.metadata["full_content"] = ""
# 불필요한 줄바꿈에 대한 제거 후 띄어쓰기 보정하여 구축
doc.page_content = spacing(doc.page_content.replace("\n", ""))
results = vectorstore.add_documents(pdf_data)
- 사용자의 입력에 대하여 PDF 검색시 동일한 띄어쓰기 구조를 갖출 수 있도록 입력된 질문에도 spacing을 적용한다.
3. 테스트
- EXCEL, CSV를 목표로 검색시 대부분 잘 찾아오기 시작
- 전체적으로 더 유사한 문서들을 기반으로 결과 출력
- 과거의 대량 데이터 기반으로 생성되는 결과는 여전히 해결되지 않음
- 이 이슈는 리트리버를 수정해서 해결 도전
4. 추가 고도화 방향
1) 프롬프트 업데이트
2) 데이터 구조 업데이트 3) 리트리버 업데이트